Janome 紹介
- Pure Python で書かれた,辞書内包の形態素解析ライブラリ
(venv) $ pip install janome
(venv) $ python
>>> from janome.tokenizer import Tokenizer
>>> t = Tokenizer()
>>> for token in t.tokenize('すもももももももものうち'):
... print(token)
...
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
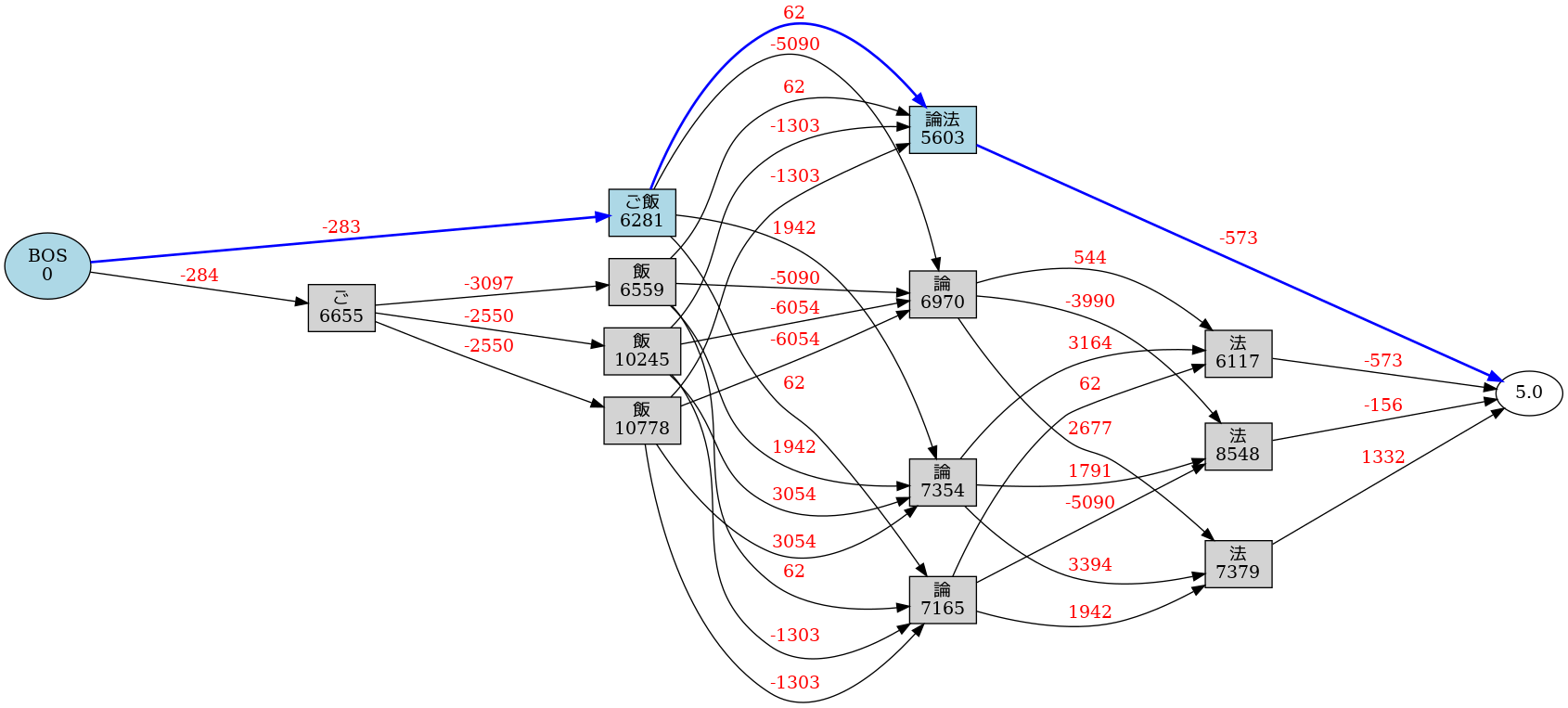
解析の様子をみてみよう
- v0.3.7 から,ラティスグラフの可視化ができるようになりました(※ 要 Graphviz)
(venv) $ echo "ご飯論法" | janome -g
ご飯 名詞,一般,*,*,*,*,ご飯,ゴハン,ゴハン
論法 名詞,一般,*,*,*,*,論法,ロンポウ,ロンポー
Graph was successfully output to lattice.gv.png
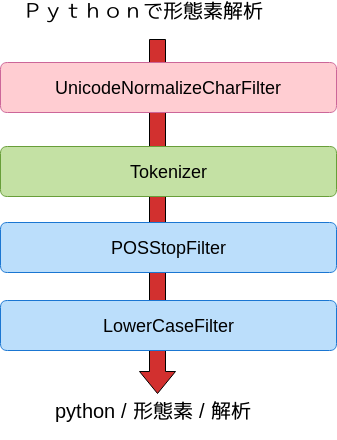
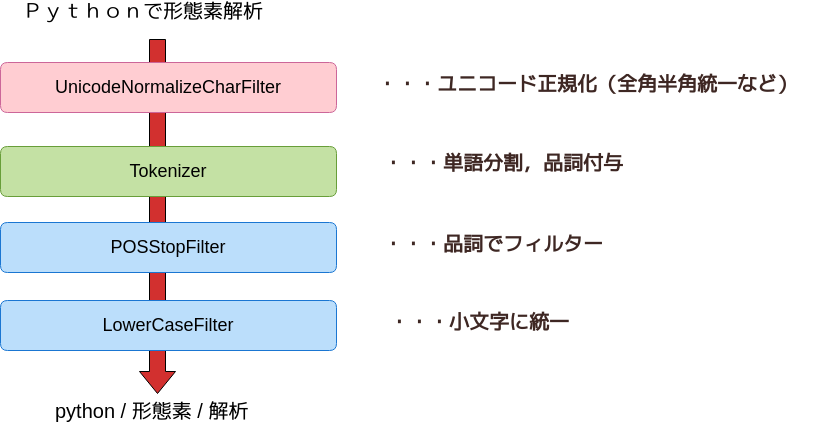
Analyzer フレームワーク
>>> from janome.tokenizer import Tokenizer
>>> from janome.analyzer import Analyzer
>>> from janome.charfilter import *
>>> from janome.tokenfilter import *
>>> text = 'Pythonで形態素解析'
>>> char_filters = [UnicodeNormalizeCharFilter()]
>>> token_filters = [POSStopFilter(['記号','助詞']), LowerCaseFilter()]
>>> tokenizer = Tokenizer()
>>> a = Analyzer(char_filters, tokenizer, token_filters)
>>> for token in a.analyze(text):
... print(token)
...
python 名詞,一般,*,*,*,*,python,*,*
形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ